
The question we’re going to be looking at today is inspired by our course Mastering GA4 With Google BigQuery.
How do I run a scheduled query in BigQuery as soon as the Google Analytics 4 daily export is complete for any given day?
If you’ve ever tried to build any sort of logic on top of the Google Analytics 4 daily export to Google BigQuery, you might have noticed one very annoying thing.
The daily export schedule is erratic at best. On one day, it might land in BigQuery before noon, on another day late in the afternoon, and on some other day it might arrive past midnight your time the following day!
Add to this the fact that it looks like there can be more than one load job from the service account associated with the export, and you have something of a mess on your hands.
Today’s question in Simmer Clips deals with this dilemma. I’ll help you solve it in a more deterministic way: instead of trying to figure out a time of day when it’s “safest” to run your queries, I’ll show you how you can build a simple pipeline with a sole purpose:
Run a scheduled query as soon as the daily export job is complete.
Video walkthrough
IMPORTANT! This article text content has been updated (11 April 2025) to use the latest features of the GA4 export in the scheduled query and to use 2nd generation Cloud Functions instead of 1st gen. The video is somewhat outdated in this sense, but you can still follow along.
If you prefer this walkthrough in video format, you can check out the video below.
Don’t forget to subscribe to the Simmer YouTube channel for more content like this.

Overview of the problem
Before we get started, let’s take a look at the problem.
Run the following query in your project.
You need the change the region specifier `region-eu` to whatever matches the Google Cloud region where your GA4 / BigQuery dataset resides.
Also, change the dataset ID in the WHERE clause to match your Google Analytics 4 export dataset ID.
SELECT
FORMAT_DATE('%F', (
SELECT
creation_time)) AS creation_date,
MIN(FORMAT_DATE('%R', (
SELECT
creation_time))) AS creation_time_UTC,
destination_table.table_id,
total_bytes_processed,
COUNT(*) AS load_jobs
FROM
`region-eu`.INFORMATION_SCHEMA.JOBS
WHERE
start_time > TIMESTAMP(DATE_SUB(current_date, INTERVAL 7 day))
AND job_type = 'LOAD'
AND destination_table.dataset_id = 'my_dataset'
GROUP BY
1,
3,
4
ORDER BY
creation_date,
creation_time_UTCWhen you run this query, you should see something like this:
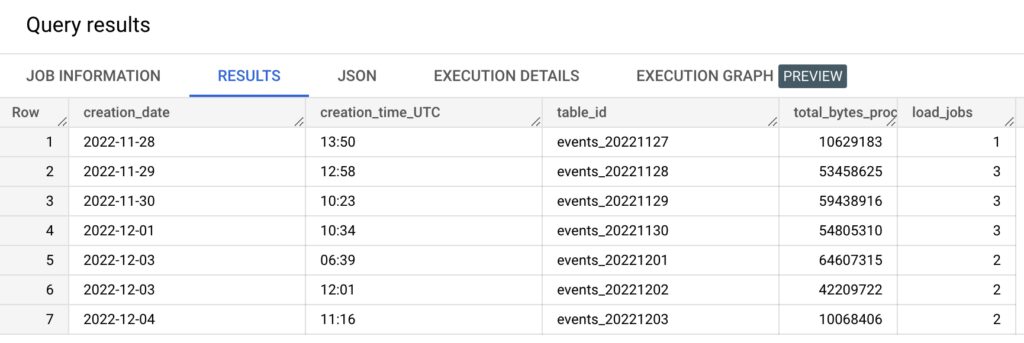
This table lists the load jobs from Google Analytics 4 over the past 7 days.
The main thing to focus on is the column creation_time_UTC. As you can see, during this 7-day stretch the load job times were actually quite consistent, with “only” four hours apart for most of them. However, the load job for the table events_20221201 happened at 6:39 a.m. the following day. That’s messed up!
If I had a scheduled query that ran at 3 p.m. UTC every day, which based on the data above would be quite a good decision, it would have missed this latecomer and I’d have a gap in my target dataset.
In order to fix this, we have to:
- Modify our scheduled query so that it only runs on demand (i.e. when manually triggered) and not with a schedule.
- Build a trigger system that runs the scheduled query as soon as a GA4 load job happens.
- Use the table_id from the load job to determine what is “today”.
This last point is very important. For our scheduled query to be correctly aligned in time, you can’t use the date of the export load job. Otherwise you would place the data in the wrong daily shard, if the daily job updated a table further in the past.
What we’ll build
Here’s a rough overview of the system that we’ll build.
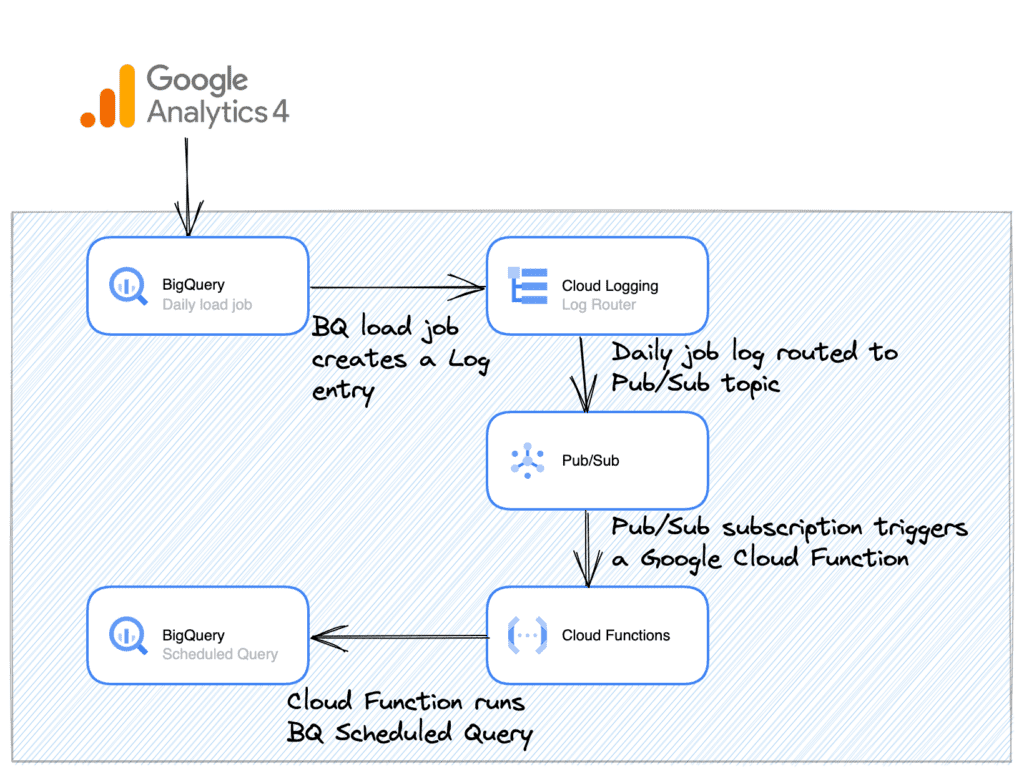
- When the BigQuery load job completes, it generates a log entry into Google Cloud Logging (this happens automatically).
- In Cloud Logging, we build a Logs Router, which sends the load job log entry into a Pub/Sub topic.
- A Cloud Function is run when the Pub/Sub topic receives the log. The Cloud Function checks the destination table ID from the log entry, and then it runs the scheduled query in Google BigQuery, setting the target date to match that of the table ID.
There might be other, more elegant ways to do this. However, using this system gives us an opportunity to learn about some useful Google Cloud Platform components and services.
1. Create the scheduled query
The first thing you’ll need to do is build the scheduled query itself. The easiest way to do this is to build the query and then save it as a scheduled query using the BigQuery console user interface.
Here’s the query I’m going to use. It’s a simple flatten query, which takes some key dimensions from the GA4 export and flattens them into a user data table I can then use later for joins.
The focus of this article isn’t what I have in the query but rather how I orchestrate it. Take a look:
SELECT
COALESCE(user_id, user_pseudo_id) AS user_id,
(SELECT
value.int_value
FROM
UNNEST(event_params)
WHERE
key = 'ga_session_id') AS session_id,
traffic_source.source AS acquisition_source,
traffic_source.medium AS acquisition_medium,
session_traffic_source_last_click.manual_campaign.source AS session_source,
session_traffic_source_last_click.manual_campaign.medium AS session_medium,
SUM(ecommerce.purchase_revenue) AS total_session_revenue
FROM
`project.dataset.events_*`
WHERE
_table_suffix = FORMAT_DATE('%Y%m%d', DATE_SUB(@run_date, INTERVAL 1 DAY))
AND COALESCE(user_id, user_pseudo_id) IS NOT null
GROUP BY ALL
ORDER BY
session_id ASCRemember to update the FROM clause to reference your BigQuery project and GA4 dataset ID.
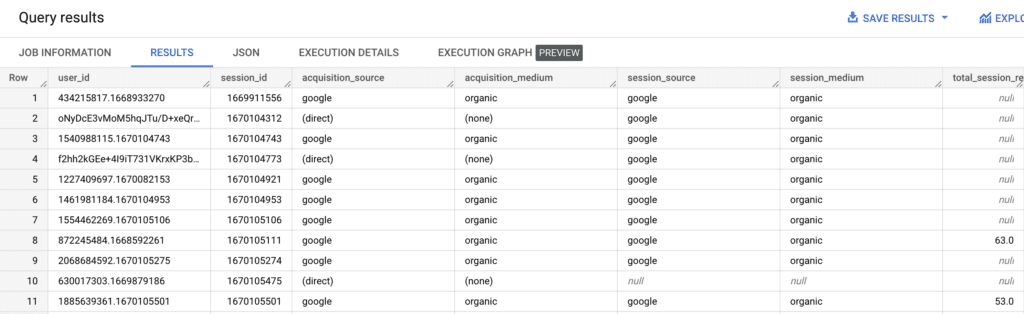
The purpose of this query is to generate a flattened table of the GA4 export. It generates a table of users and sessions, including the original acquisition campaign of the user, the session source/medium and the total revenue generated for each session the user had.
The key part of this query is in the WHERE clause. See the @run_date thing? That’s automatically populated by the run time of the scheduled query.
What you’ll learn later is that we can actually manipulate this run time to match the table that the GA4 data was loaded to. This is an absolutely critical part of this process because it allows us to safely run the scheduled query on backfilled data too.
This is a sample output of the query:
When you’re happy with the query, click the SCHEDULE button in the BigQuery console top button and then Create new scheduled query.
The three options you need to pay attention to in the scheduled query settings are:
- Set the repeats option to On-demand. We want to run this query only when triggered manually (i.e. by the Cloud Function we’ll build later).
- Use a variable in the Destination Table ID.
- Set the query to Overwrite rather than Append.
Point (2) is important. If you want the table ID to have a similar YYYYMMDD suffix as the GA4 export, you can set the field to something like this:
events_{run_time-24h|"%Y%m%d"}
Here, the syntax in the curly braces basically takes the day before the scheduled query run time and generates a YYYYMMDD string from it. That way if the run time of the scheduled query is May 25th, 2023, the destination table ID for the scheduled query becomes:
events_20230524
And this will match the destination table ID of the GA4 export, too, as you’ll see when we build the Cloud Function.
Set the query to Overwrite the destination table. This is because the source of the query is the entire GA4 daily table, so it doesn’t matter if you overwrite the destination table each time the query is run. As I mentioned earlier, the GA4 daily job can happen multiple times per day, and it’s possible for backfilling to happen, too.
By having the Overwrite option selected, it ensures the flattened table is always generated from the most recent state of the source table (the GA4 daily export table).
2. Create the Logs Router
We now have our scheduled query built, waiting to be triggered with the GA4 load job.
But that’s the end of the pipeline. We need to build everything else now.
The Logs Router looks for a log entry that is generated when a GA4 daily load job is complete. We use this as the trigger event for our entire pipeline setup.
This log entry is then shipped to a Pub/Sub topic, which starts the Cloud Function.
Now, head over to Logs Router and click the CREATE SINK button in the top to create a new router sink.
- Give the sink a name.
- Choose Google Cloud Pub/Sub topic as the destination.
- From the list of available Pub/Sub topics, click to create a new topic.
- Provide a Topic ID, and leave all the other settings as their defaults.
- Click CREATE TOPIC.
- In the Build inclusion filter, copy-paste the following code. Modify the dataset ID on line 3 to match the dataset ID of your GA4 export dataset.
protoPayload.methodName="jobservice.jobcompleted"
protoPayload.authenticationInfo.principalEmail="firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.datasetId="my_dataset"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.tableId=~"^events_\d+" - Click CREATE SINK once you’re done.
The inclusion filter looks for logs that have the method jobservice.jobcompleted and were specifically generated by the firebase-measurement@... service account. This is the account that performs all the Google Analytics 4 export jobs.
Here’s what the Logs Router should look like:

Just one thing remains! We need to build the Google Cloud Function that is subscribed to the Pub/Sub topic receiving these load job log entries.
3. Build the Google Cloud Function
Google Cloud Functions are serverless, well, functions that can be run on-demand in the cloud. Their purpose is to perform small, low-intensity tasks at scale.
In this case, we want the Cloud Function to subscribe to the Pub/Sub topic we created above.
We then want it to parse the log entry for the destination table details, so that we can calibrate the run time of the scheduled query to match the date of the table that the GA4 daily job created (or updated).
So, head on over to Cloud Run and click Write a function in the header bar. You can also browse straight to function creation by following this link (make sure you are in the correct Google Cloud project).
- Keep Use an inline editor… selected.
- Give the function a descriptive name.
- Choose a region for the function – this can be anything you like but it would make sense to have the regions of your BigQuery datasets and related Google Cloud components be the same.
- Select Node.js 22 as the runtime.
- Click + Add trigger to add a Pub/Sub trigger to the function.
- In the appropriate section, select the Cloud Pub/Sub topic you created in the previous section.
- Select the same region for the trigger as you’ve selected for all the services created thus far.
- Click Save trigger when done.
This is what it should look like:
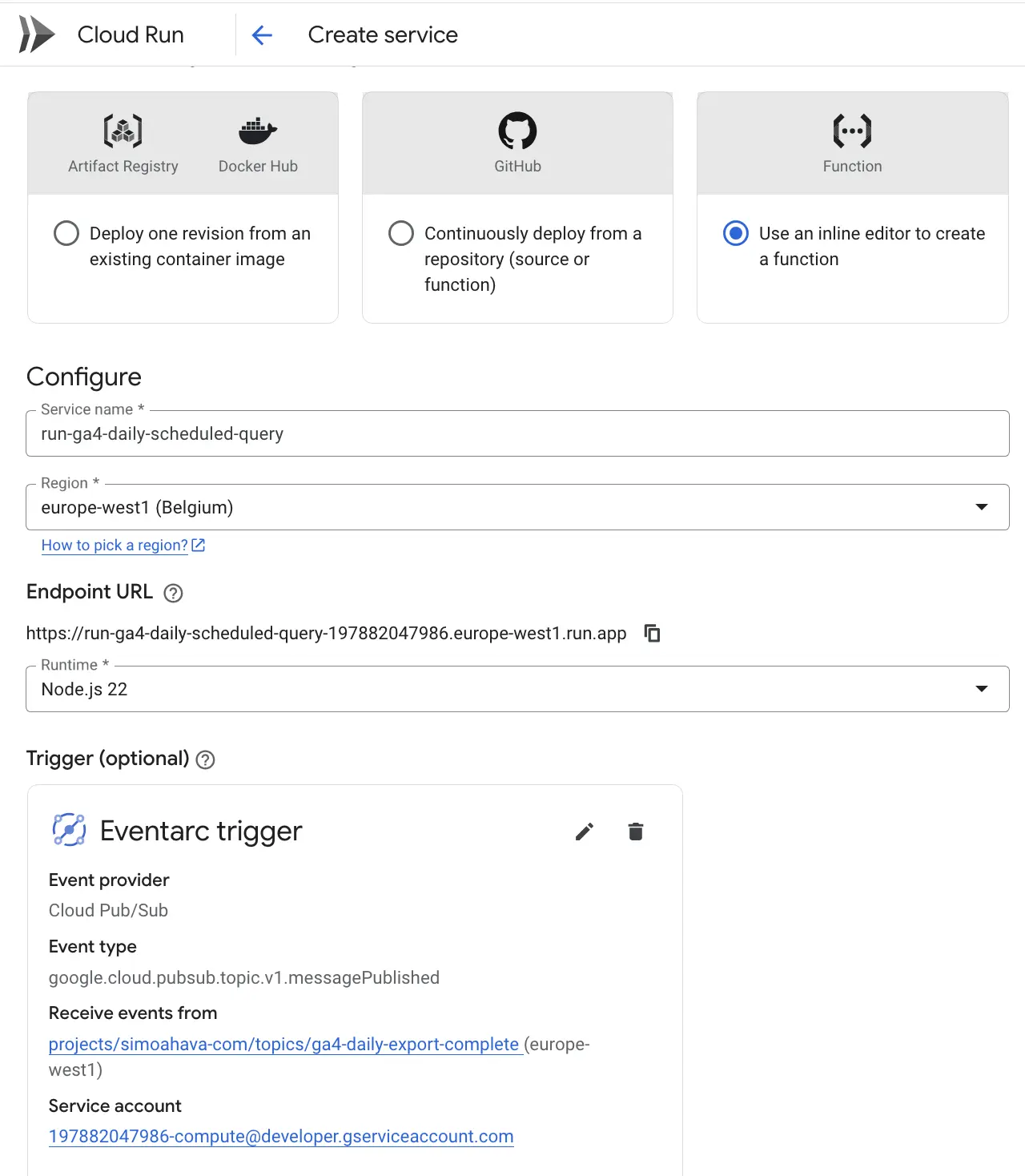
- You can keep the rest of the settings with their default values. Click Create to create the function.
Next, an inline editor starts. This is where you’ll type the actual JavaScript code that gets executed when the GA4 export has taken place.
In this function, we’re going to invoke the on-demand scheduled query in BigQuery.
First, edit the package.json file to update the dependencies of the function.
In the next screen, we need to add the function code itself. This is what gets executed when the function is run.
- Keep Node.js as the runtime (choose the latest non-Preview version).
- Click package.json to edit its contents.
- Add the following line in the “dependencies” property:
"@google-cloud/bigquery-data-transfer": "^5.0.1"
This is what package.json should look like (the version numbers might be different when you try this solution):

- Select index.js from the list of files to activate the code editor.
- Edit the Function entry point field on top of the editor to be
runScheduledQuery. - Copy-paste the following code into the editor.
const functions = require('@google-cloud/functions-framework');
const bigqueryDataTransfer = require('@google-cloud/bigquery-data-transfer');
functions.cloudEvent('runScheduledQuery', async (cloudEvent) => {
// Update configuration options
const projectId = '';
const configId = '';
const region = '';
// Load the log data from the buffer
const eventData = JSON.parse(Buffer.from(cloudEvent.data.message.data, 'base64').toString());
const destinationTableId = eventData.protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.tableId;
// Grab the table date and turn it into the run time for the scheduled query
const tableTime = destinationTableId.replace('events_', '');
const year = tableTime.substring(0, 4),
month = tableTime.substring(4, 6),
day = tableTime.substring(6, 8);
// Set the run time for the day after the table date so that the scheduled query works with "yesterday's" data
const runTime = new Date(Date.UTC(year, month - 1, parseInt(day) + 1, 12));
// Create a proto-buffer Timestamp object from this
const requestedRunTime = bigqueryDataTransfer.protos.google.protobuf.Timestamp.fromObject({
seconds: runTime / 1000,
nanos: (runTime % 1000) * 1e6
});
const client = new bigqueryDataTransfer.v1.DataTransferServiceClient();
const parent = client.projectLocationTransferConfigPath(projectId, region, configId);
const request = {
parent,
requestedRunTime
};
const response = await client.startManualTransferRuns(request);
return response;
});- Change the
projectIdvalue to match the Google Cloud Platform project ID where you build your scheduled query. - To get values for
regionandconfigId, browse to scheduled queries, open your scheduled query, and click the Configuration tab to view its details. regionvalue should be the Google Cloud region of the Destination dataset, so click through to that to check if you don’t remember what it was.configIdis the GUID at the end of the Resource name of the scheduled query.
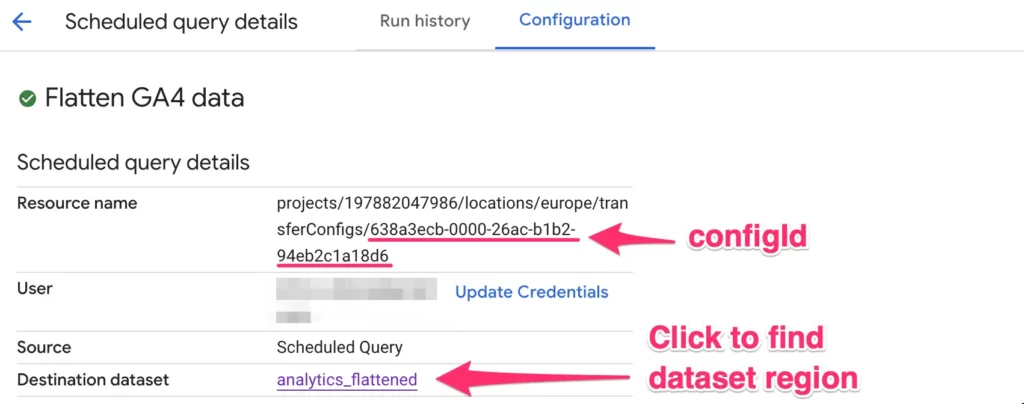
This is what the relevant part of my function looks like:

My destination dataset is multi-region EU, hence the 'eu' value for region. If your dataset is in a specific region, the value would be something like us-west1, for example.
Once you’re happy, click DEPLOY in the bottom of the screen to deploy the function.
The purpose of the function is to take the log entry and parse it for the destination table ID (events_YYYYMMDD).
The date part is then extracted, and a new proto-buffer Timestamp object is created from that date object, as this is required if you want to manually set the run time of the query.
The only special thing we do is move one day forward in time, because we want the run time to be one day after the destination table ID that was updated.
This is to mirror how the GA4 daily export works – it always updates yesterday’s table (or a table further in the past).
When you click DEPLOY, it will take a moment for the function to be ready for action. Once the spinner stops spinning and you see a green checkmark, you’re good to go.
4. Test the setup
I couldn’t figure out a way to manually test the Cloud Function, as it would require generating an identical log entry as those created by the GA4 export service account.
If you have an idea how to test this with a mock log entry, please let me know in the comments!
There are typically 2–3 daily load jobs from GA4, so you’ll need to wait some hours in the afternoon for a load job to be generated.
The best way to check if your scheduled queries are running is to go to the BigQuery user interface and check the PROJECT HISTORY tab at the bottom of the screen.
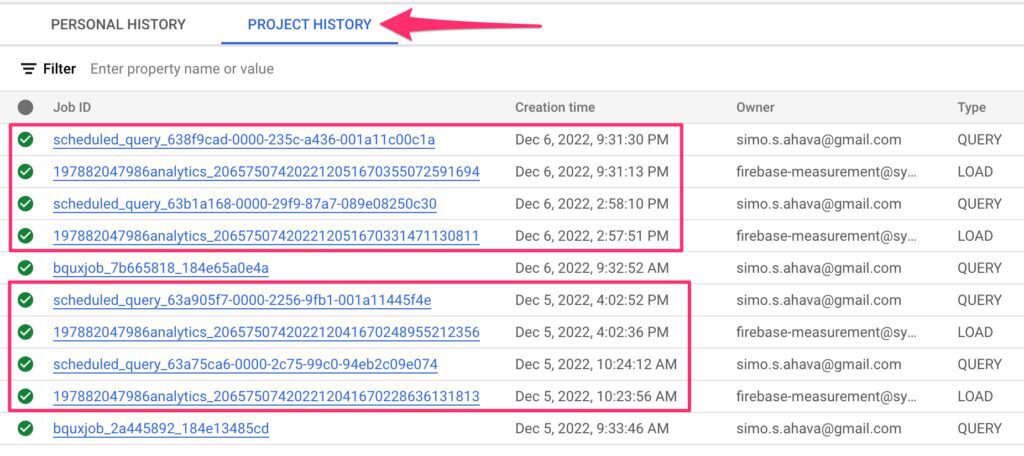
Each LOAD job where the owner is firebase-measurement@... should be followed shortly by a QUERY job with a Job ID that starts scheduled_query.... If you see this, it means your setup is working, and you can verify this by visiting the dataset where your scheduled query writes its output to.
If you don’t see this, there’s a problem somewhere along the line, and a good first step is to visit Logs Explorer and look for error logs related to one or more of the components in your setup.
Typical culprits are an incorrectly configured Logs Router or a mistake in the Cloud Function.
Summary
It might be a good idea to double-check your setup by watching the video as well.
As far as Google Cloud Platform pipelines go, this is not a complicated setup. You actually only had to configure three things:
- The scheduled query that you want to run on-demand,
- the Logs Router that listens for load job complete entries,
- and the Cloud Function that triggers with the log entry and runs the scheduled query.
Yes, you created a Pub/Sub topic during the process, but the beauty of the Google Cloud Platform is that this was embedded in the flow of setting up the pipeline itself, and you never had to actually configure the Pub/Sub topic or its subscriptions separately, it was all done without having to break your stride.
This is why the Google Cloud Platform is such a pleasure to work with. The way it guides the user through interconnected components is way ahead of its competition (in my opinion).
I hope you found this informational, and I hope you’ve been bitten by the Google Cloud Platform bug (if you weren’t a fan already). Let me know in the comments if you have any questions about the setup!
If you’ve built this funnel some other way, I’d love to hear more about your approach, too.



33 Responses
The Cloud Functions Gen 1 used in the post no longer works. As Simo always says that non-technical people should not be afraid to get technical I got into it (with friendly advice from gen AI) and found a way to keep using the same logic with a Cloud Run Function Gen 2.
I figured I would save some people’s time and explained what I did in a post that I left on Medium.
https://medium.com/@raphaelcalgaro/updating-team-simmers-ga4-trigger-with-cloud-run-gen-2-a-smarter-way-to-automate-bigquery-queries-9073bdd6ddc4
Thanks for the push – I have now updated the code samples and the screenshots in the article to use Cloud Run Functions.
Hi Simo,
Thank you for your article.
I tried to implement it, first out of curiosity and then for an internal POC.
Unfortunately, the pub/sub topics doesn’t receive anything, so the Cloud Function isn’t triggered. After some investigation, it seems that the log filter used to create the sink isn’t returning anything.
protoPayload.methodName=”jobservice.jobcompleted”
protoPayload.authenticationInfo.principalEmail=”firebase-measurement@system.gserviceaccount.com”
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.datasetId=”my_dataset”
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.tableId=~”^events_\d+”
In fact, at the time of installation, I had tested this filter in the Logs Explorer, but I couldn’t see any data but I didn’t investigate why any further. And as I tried to debug, I noticed that the .methodName filter value was different in my Load logs (google.cloud.bigquery.v2.JobService.InsertJob) and I didn’t see any value for the .serviceData.[…] filters. (I found the log thanks to your BigQuery query, using the date and time).
So, in fact, I think that the pub/sub topic is not being fed as no logs are being kept in the filter.
Do you have any idea why this is different? Has BigQuery changed its log structure for this job? Do I need to change the filter?
Hi
It’s difficult to say what the problem might be – I just checked and the pipeline has been running uninterrupted with that particular inclusion filter for a while, definitely no changes in the log signature at least in my tests.
You can always go to BigQuery and browse through the Job History for the Project. There you can see the load jobs. Check the Job ID for any given load job and then start going through the Logs Explorer entries initiated by the “firebase-measurement…” account to see what the signature of the log entry is for your load jobs.
I have a few tables to update with this pub/sub approach and I am trying to figure out which parts I can reuse instead of doing all the time.
Another oddity worth putting out to the hive mind:
Many of our scheduled queries do a delete first, then insert. So if GA4 updates 20230719’s tables, the scheduled query will delete all rows where event_date = 20230719, then insert the select statement for that 20230719 date.
The problem for us occurs when GA4 pushes updates VERY quickly. It happens from time to time that the Pub/Sub topic will trigger the cloud function within 30 seconds. Don’t ask me why, but I can’t control Google. When this happens, some scheduled queries are run twice in a short period of time. The problem, specifically, is when the delete portion from scheduled query 1 and 2 complete before the insert portion of scheduled query 1 and 2 complete. It makes a mess of our data.
Any ideas for this?
I’ve looked into finding a way to limit concurrent DML mutations per table to 1 (appears to not be possible).
Simo – Thanks for this guide.
Two questions for you and/or your readers:
1 // How would you revise the cloud function to support multiple data transfer GUIDs? We use scheduled queries to aggregate the ga4 base tables for various initiatives. Is it just duplicating the function for every scheduled query? Or should we utilize a loop within one function?
2 // I’m quite confused by the run_date/run_time parameter and the +/-24 hour logic you use, specifically in instances where the ga4 tables are being re-run for days further beyond yesterday in the past. If GA4 is exporting for, say, 5 days old tables (we see it from time to time, ourselves), how does the scheduled query know to overwrite the right date if we keep using -1/+1?
Hi
1) I’ve never tried this but I think the easiest is to simply have multiple cloud functions rather than risk timeouts or similar by running everything in a single function. Separation of concerns, in other words.
2) The timestamp of the inserted table by GA4 is what’s used to calculate the base date for the table created by the scheduled query. So the starting point in the cloud function should always reflect the date of the table that GA4 is trying to create / update.
Hello, Simo! Thank you for the post, but i am facing a problem:
My everything is working except the final table creation.
My “events_” table has been created with the suffix “19691231”, as if i was in unix starting time 1970-01-01.
I dont know what to do or what to debug for. Any hints?
Hi
Make sure that you are working with the regular GA4 daily batch export and not with just the intraday, for example, nor with some custom table you’ve created. This solution works only with the default GA4 daily batch export.
Simo,
Thanks so much for this walkthrough! Super helpful!! What would we need to alter on this if we wanted to run a scheduled query that is triggered when this flattened table is generated? I would be interested in running a query against this flattened table without having to manually run it or check to see if the table is present.
Hi!
I guess you could update the Cloud Function to wait for the first scheduled query (the one that generates the flattened table) to complete and then run another scheduled query (the one that runs against the newly created flattened table). There are probably easier ways to go about this, though, but that’s the first thing that came to my mind.
hi Simo, thanks a lot for that! it’s a great introduction to GCP and a tiny bit of data engineering. 🙂 i’ve been using your process for a month now, but still trying to understand every bits and pieces.
My question: why do you have “month – 1” on row 19 of your Cloud Function?
Let’s say that today (Feb 1st), GA4 updates my table events_20230130, so two days later (which happens a lot for me). Then destinationTableId = ‘events_20230130’, so tableTime = ‘20230130’, so month = ’01’. So then runTime = new Date(Date.UTC(2023, 01 – 1, 31, 12)).
But month = ‘0’ here, so that shouldn’t work right? Besides, that scheduled query will have runTime = Jan 31st, which is yesterday. Will it still run today?
Hi!
That’s how JavaScript works – `new Date()` constructor takes integers for the date and time components, and the month components always starts from 0 (January). The date string in the GA4 export uses the regular date, so to get the actual month you need subtract one from it.
And yes, everything will work as intended. The GA4 export comes with a destination table of 20230130. The Cloud Function sets the runtime of the scheduled query to 31st Jan, 2023. The scheduled query itself then has the “INTERVAL 1 DAY” in the `DATE_SUB` function. It would of course work without the day+1 and DATE_SUB – I just decided to keep the scheduled query consistent with how you would “normally” approach the query (so yesterday’s data).
Hi Simo –
Just wanted to express my thanks for this blog post. I appreciate the knowledge sharing of multiple different aspects of GCP. Currently building a pipeline to send data from GA4/BigQuery to Redshift, and was able to extrapolate my process from the lessons in this video.
My aspiration is to move from doing data analytics to data engineering and this is just what I needed!
Happy Holidays from NYC 🙂
Hi Justin!
Thanks – I’m very glad you found the article useful 🙂
Best regards,
Simo
Hi Simo, thanks for this nice article. I implemented the solution and it works as expected. However, I would like the destination table to be a date-partitioned table rather than a sharded table. How would you suggest to approach this challenge? Is this something that should be changed in the logic of the cloud function?
Hi Maxime!
Yes, when you create the Scheduled Query, you can specify which field to use for partitioning, e.g. `event_date` 🙂
If you change it to partitioning, and you keep the overwrite setting enabled, won’t this affect the entire table, so all partitions/ dates? Or is this not the case with partitions? In addition, if you have historical data you want to load into this sharded table, it would require you to backfill. Not entirely sure how to do this.
Hey Martijn!
I suppose in that case you would need to modify the schedule query to use DDL instead, drop the partition that needs to be overwrited, and then recreate it?
The sharded table use case is easier, because then the scheduled query is just configured to write to the relevant shard, and overwriting the shard doesn’t overwrite all the other shards. This is the use case I walk through in the article/video.
Simo
Hi Simo,
I understand, you can’t cover all options 🙂
For those wanting to go the “partition route”, you need to change 2 things:
1. in your scheduled query, there’s no need for the variable in the Destination Table ID. Simply replace events_{run_time-24h|”%Y%m%d”} with the name of your table.
2. Add the following code to your query:
delete
`project.tableset.table`
where
event_date = date_sub(@run_date, interval 1 day);
insert into
`project.tableset.table`
With these 2 minor changes, the instruction was perfect for my needs. Thanks for the great tutorial Simo!
Hi Martijn,
“delete” should be defined just after “from” clause?
Can you share at least that part of code? I have trouble setting up Your solution.
The code I’ve included in step 2 of the update should go first, so before the select statement. All the way at the top. And to be clear, you need to disable the option to set a destination altogether. This is already sorted in the query itself.
delete
`tidy_data.events`
where
event_date = date_sub(@run_date, interval 1 day);
insert into
`tidy_data.events`
select
user_pseudo_id,
…
Hi there, I thing your date partitioning solution is what I also need, but can’t understand where to place the “delete” and “insert into” parts, can you pls help?
Exactly the same here 🙁
The solution to this problem is partition decorators. You can set the destination table to your_table${run_time-24h|”%Y%m%d”} and have it overwrite. It will only overwrite that partition.
Hi Simo and thx for this,
I run the load-jobs query on my dataset, but I found something different from expected.
In particular, it looks like everyday the load is performed three times minimum, going back in time.
For example: “2022-12-05” (creation_date) is associated with “events_20221202”, “events_20221203” and “events_20221204” (table_ids). Is this because of the 72h post-processing of GA4 ?
Moreover, for certain “creation_dates”, I find 6 table_ids associated with those! For example, creation_date = “2022-12-04” and table_id = “events_20221130” or “events_20221101”.
I expected a relationship like “creation_date” associated with the previous day “table_id” only, like your example above. Thanks!
Hi!
Yes, there’s a 72h update window so historical updates are not out of the question. Per Google’s documentation, sometimes the historical updates can go even further back if they’re fixing bugs in data collection retroactively, for example. That’s why the Cloud Function gets the run time from the destination table ID and *not* from the creation_time of the daily job!
Also, multiple loads per day is the norm – for some reason the same table gets loaded more than once with the export job.
Thanks Simo! loving this new clips series
Hi! Really insightful blog post, thanks for this! I was wondering whether you also have a way of incorporating a backfill with this set-up?
I have some tables paired with manual scheduled queries that I want to switch over to this set-up. Obviously these already contain quite some data accumulated from the past and I do not want to lose this data. Perhaps an easy task, but it does not seem that straightforward to me.
Hi! I think easiest would be to use DDL to loop through the historical tables and dynamically update them. Check this earlier article for an example of a DDL looping through tables: https://www.teamsimmer.com/2022/11/15/how-do-i-change-the-table-expiration-in-google-bigquery/
A poor man’s solution (avoiding cloud functions and super precise timings) – you could maybe create a sink of the update events into a BQ table and then have your scheduled query / stored procedure handle the create/replace. This could be less scary for those unfamiliar with Node/Python or if your cloud team doesn’t want you stepping outside the “walled garden” of BigQuery. It’s definitely less flexible going this route could reduce fear factor for lazy martechies, “non-technical marketers” or disaffected data scientists. The scheduled query could be set to run at whatever frequency and while it wouldn’t be run immediately it could do a simple check every hour or so and be timely enough for most use cases. Getting those historic changes accounted for is the most critical / stressful imo…
Hey Adam!
Yeah, there are many ways to skin the cat 🙂 A slightly “richer man’s solution” would be to use Gen2 of GCF and EventArc, although that might not actually be any simpler, even if it’s somewhat more straightforward.
But one of the key values of Simmer is to destroy this myth of the “non-technical marketer”. I believe in not sugarcoating things when the payoff for learning things the hard way outweighs other solutions. That’s one of the reasons I think this article could be valuable – it solves the problem, yes, but it also introduces the reader to a number of components in the GCP stack that can be really valuable in future data engineering work. Hopefully I manage to demystify them somewhat!
Thanks for the feedback – your approach is sound but as you mention it does still surface the problem of historical updates and avoiding unnecessary query runs.